


A Data Science pipeline is a process that transforms raw data into useful solutions to solve business issues.
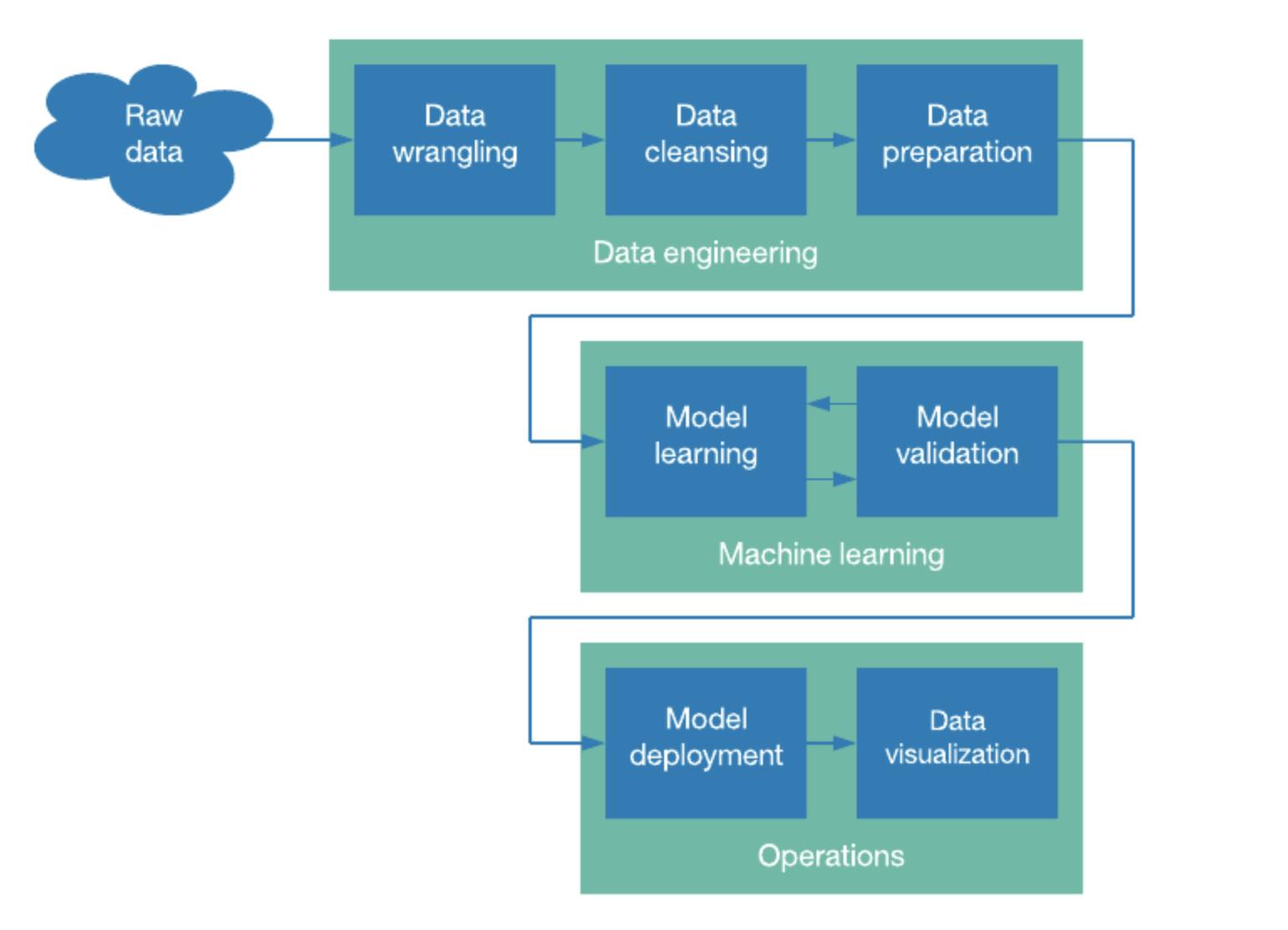
There are various steps in the data science pipeline, including
Obtaining information
This is where data is collected and processed from internal, external, and third-party sources into a useful format (XML, JSON, .csv, etc.).
Data cleansing
This is the most time-consuming step. Anomalies in data, such as duplicate parameters, missing values, or useless data must be cleaned before a data visualization can be created.
Data cleansing can be classified into two types:
a) Examining data to look for errors, missing numbers, or entries that have been corrupted.
b )Cleaning data entails filling in gaps, correcting errors, deleting duplicates, and discarding obsolete records or data.
Data exploration and modeling
After the data has been completely cleaned, data visualization tools and charts can be utilized to detect patterns and values. This is where artificial intelligence (AI) techniques come into play. You can detect patterns and apply specific rules to data or models using classification accuracy, confusion matrix, logarithmic loss, etc.
Data interpretation
This stage aims to uncover and link insights with your data findings. You can then use charts, dashboards, or reports/presentations to present your results.
I tried to provide all the important information on Data Science pipeline. I hope you will find something useful here. Happy Learning !!