


In this Blog, I will be writing about all the basic stuff you need to know about Pandas.
What is Pandas?
Pandas is an open-source library that is made mainly for working with relational or labeled data .This library is built on the top of the NumPy library. Pandas is fast and it has high-performance
Why do we use Pandas?
Through pandas, you get aware with your data by cleaning, transforming, and analyzing it. For example , we want to explore a dataset stored in a csv format. Pandas will convert CSV into dataframe - a table basically and then let you perform many tasks easily.
Average,max,median or min of each column
Clean the data by doing things like removing missing values and filtering rows or columns by some criteria
- Visualize the data using data visualisation libraries like matplotlib,seaborn
Getting started with Pandas
Install Pandas
pip install pandasSample Data - Here I will use the famous Iris dataset .It comprises of the sepal length and petal length of the flowers.
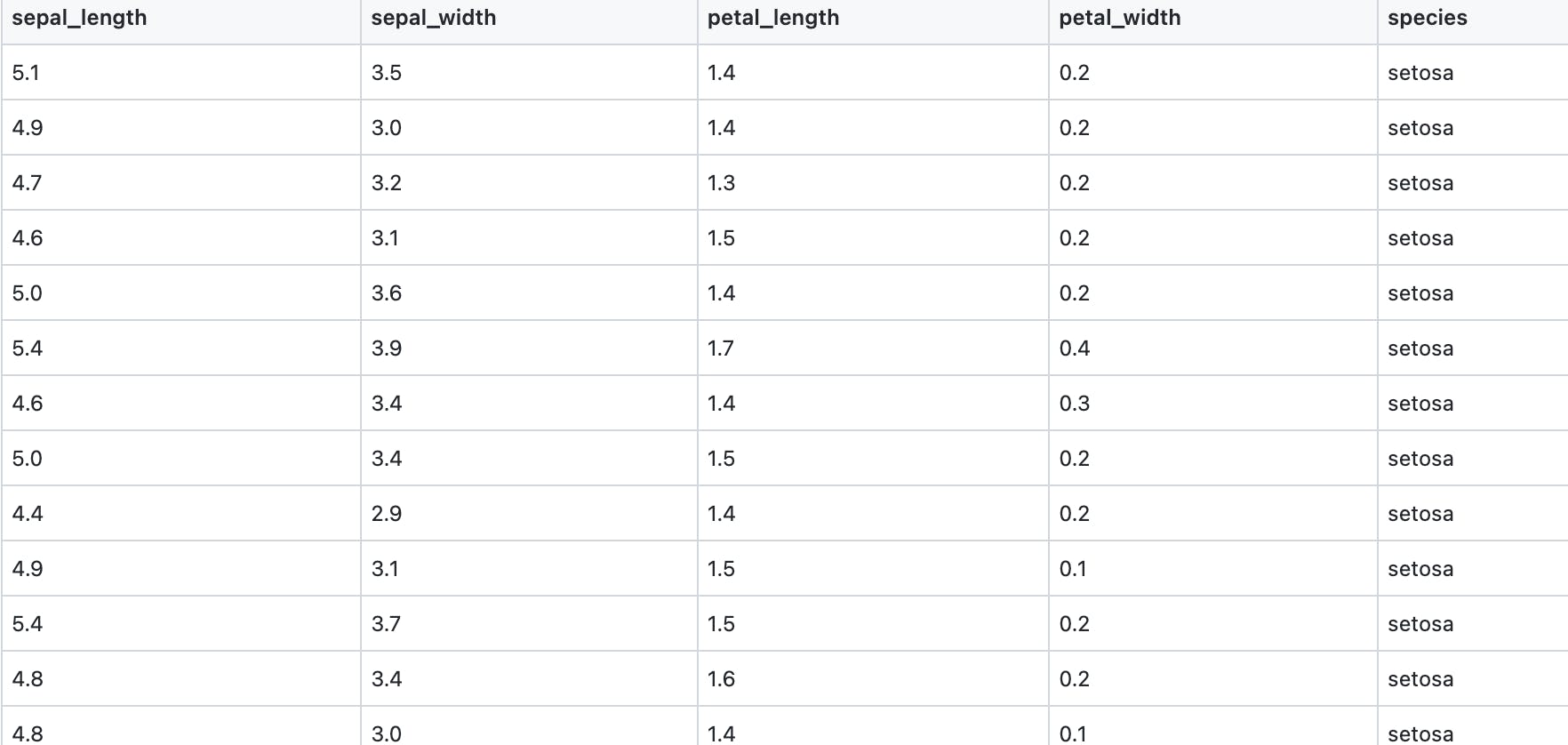
Load Data into Pandas
import pandas as pd
df = pd.read_csv("csv_file_path")
The above code snippet reads data from a source and loads it into Pandas internal data structure called DataFrame.
Understanding Data
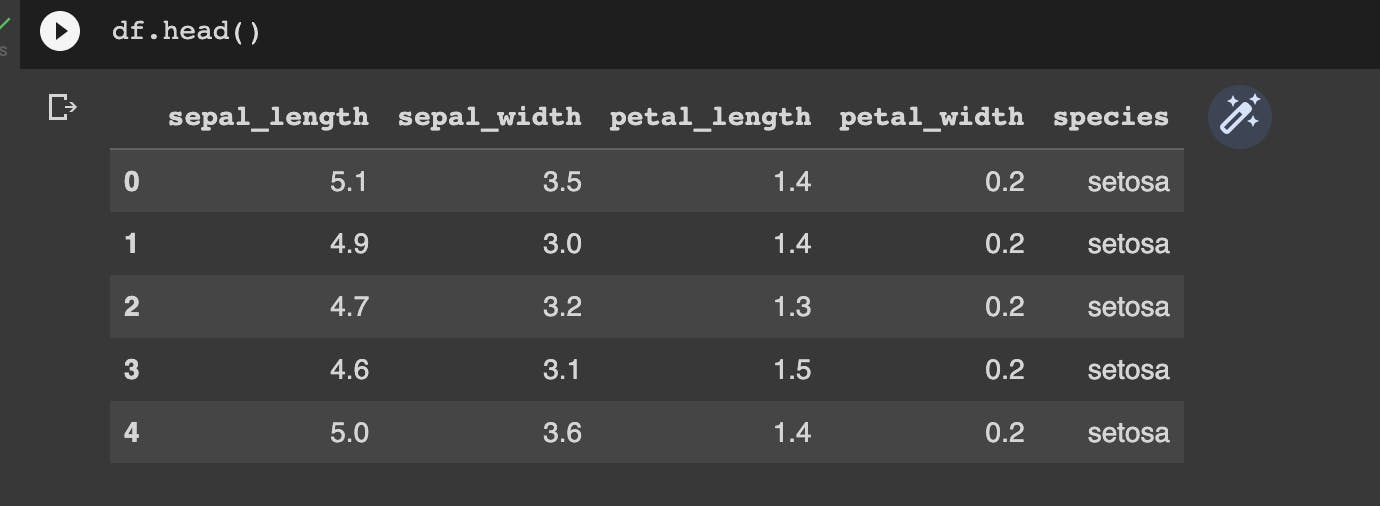
# 1. access the first n rows of a dataframe
df.head()
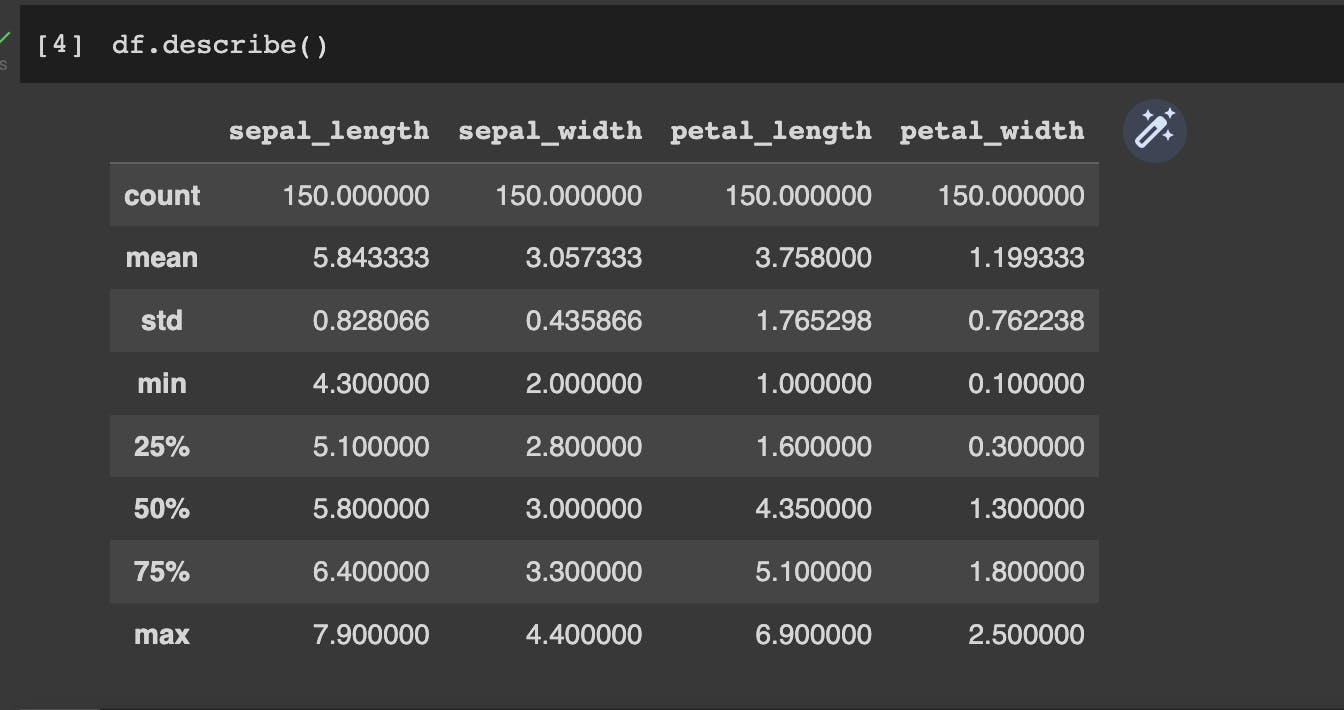
# 2. Some statistical information about your data
df.describe()
I tried to provide all the important information on pandas for beginners. I hope you will find something useful here. Happy Learning !!